一个典型的HDFS系统包括一个NameNode和多个DataNode。NameNode维护名字空间;而DataNode存储数据块。
DataNode负责存储数据,一个数据块在多个DataNode中有备份;而一个DataNode对于一个块最多只包含一个备份。所以我们可以简单地认为DataNode上存了数据块ID和数据块内容,以及他们的映射关系。
一个HDFS集群可能包含上千DataNode节点,这些DataNode定时和NameNode通信,接受NameNode的指令。为了减轻NameNode的负担,NameNode上并不永久保存那个DataNode上有那些数据块的信息,而是通过DataNode启动时的上报,来更新NameNode上的映射表。
DataNode和NameNode建立连接以后,就会不断地和NameNode保持心跳。心跳的返回其还也包含了NameNode对DataNode的一些命令,如删除数据库或者是把数据块复制到另一个DataNode。应该注意的是:NameNode不会发起到DataNode的请求,在这个通信过程中,它们是严格的客户端/服务器架构。
DataNode当然也作为服务器接受来自客户端的访问,处理数据块读/写请求。DataNode之间还会相互通信,执行数据块复制任务,同时,在客户端做写操作的时候,DataNode需要相互配合,保证写操作的一致性。
下面我们就来具体分析一下DataNode的实现。DataNode的实现包括两部分,一部分是对本地数据块的管理,另一部分,就是和其他的实体打交道。我们先来看本地数据块管理部分。
安装Hadoop的时候,我们会指定对应的数据块存放目录,当我们检查数据块存放目录目录时,我们回发现下面有个叫dfs的目录,所有的数据就存放在dfs/data里面。
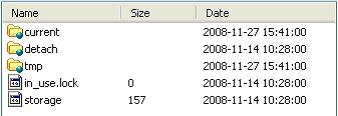
其中有两个文件,storage里存的东西是一些出错信息,貌似是版本不对…云云。in_use.lock是一个空文件,它的作用是如果需要对整个系统做排斥操作,应用应该获取它上面的一个锁。
接下来是3个目录,current存的是当前有效的数据块,detach存的是快照(snapshot,目前没有实现),tmp保存的是一些操作需要的临时数据块。
但我们进入current目录以后,就会发现有一系列的数据块文件和数据块元数据文件。同时还有一些子目录,它们的名字是subdir0到subdir63,子目录下也有数据块文件和数据块元数据。这是因为HDFS限定了每个目录存放数据块文件的数量,多了以后会创建子目录来保存。
数据块文件显然保存了HDFS中的数据,数据块最大可以到64M。每个数据块文件都会有对应的数据块元数据文件。里面存放的是数据块的校验信息。下面是数据块文件名和它的元数据文件名的例子:
blk_3148782637964391313
blk_3148782637964391313_242812.meta
上面的例子中,3148782637964391313是数据块的ID号,242812是数据块的版本号,用于一致性检查。
在current目录下还有下面几个文件:
VERSION,保存了一些文件系统的元信息。
dncp_block_verification.log.curr和dncp_block_verification.log.prev,它记录了一些DataNode对文件系定时统做一致性检查需要的信息。
更多请看:http://caibinbupt.iteye.com/blog/282580
作者是写了一个系列,我认为其中这一节即第9节 值得一看,其他是讲源码的。
分享到:




相关推荐
Hadoop源代码分析(完整版).pdf
深入云计算:Hadoop源代码分析(修订版)
Hadoop源代码分析完整版.pdf
Hadoop源代码分析 分析了hadoop的一些包,一些类 ,需要对hadoop深入了解的可以看看
Hadoop源码分析(完整版),详细分析了Hadoop源码程序,为学习Hadoop的人提供很好的入门指导
Hadoop源代码分析 高清完整中文版PDF下载 Hadoop源代码分析
Hadoop的源代码分析
Hadoop源代码分析完整版,非常全面的hadoop源码解析
Hadoop源代码分析完整版
Hadoop源码分析视频下载
Hadoop 源代码分析 完整版
caibinbupt的Hadoop源码分析完整版,包括 HDFS 和 MapReduce。 HDFS: 41章 MapReduce: 14章